If It Fits, It Sits:
Qwen 3.6 35B
We are releasing our next pair of ByteShape models: Qwen 3.6 35B NTP (next-token prediction) and Qwen 3.6 35B MTP (multi-token prediction).
The short version: clear improvements across all hardware we tested. For most devices, the recommendation is refreshingly simple:
Pick the largest ByteShape model (Model 5) if it fits in your memory. It is possible to squeeze out better performance with more aggressively quantized models, but Model 5 stands out for both quality and TPS. If you are not fortunate enough to be able to fit it, Models 3 and 2 are good alternatives.
That is not always how quantized model selection works. Sometimes the fastest model gives up too much quality. Sometimes the highest-quality model is too slow. Sometimes the “obvious” choice changes from one GPU to another.
For this release, the pattern is cleaner. Model size mostly decides what fits. Among the models that fit, Models 5, 3, and 2 generally give the best quality-speed trade-off.
TL;DR
- We are releasing NTP and MTP ShapeLearn GGUF quantizations for Qwen 3.6 35B.
- For most GPU users, the recommendation is simple: choose the largest ByteShape model that fits your memory and context needs.
- On 24+GB GPUs,
GPU-5is the main recommendation for both quality and throughput. - On 16GB GPUs,
GPU-3is the main NTP recommendation, whileMTP-GPU-2is the practical MTP recommendation because of the extra MTP memory footprint. - MTP delivers a meaningful token-generation boost on GPUs, generally around 20–40% in our tests, while preserving benchmark quality.
- MTP is currently not a great fit for CPU inference because prompt processing is already the bottleneck, and MTP exacerbates that pressure.
A bit of benchmarking methodology updates
We made two small but meaningful benchmarking methodology changes for this release:
1. Broader comparison set
We expanded the set of quantized models we compare against. Instead of focusing heavily on one publisher, we now include more publishers and select fewer models from each.
The goal is to compare against the models that each publisher appears to treat as their strongest or most recommended variants. We infer this from their published benchmark results, release notes, and model-card recommendations.
This is not perfect, but it keeps the benchmarking scope manageable. Since full quality evaluation takes time, we focus on a smaller set of strong candidates rather than a large set of models few users are likely to choose.
2. MMLU excluded for this release
We excluded MMLU from the headline benchmark score for this release.
The reason is not that Qwen 3.6 35B lacks knowledge. The issue is answer-format compliance. MMLU is strict: the model has to answer in the expected format. Qwen 3.6 35B sometimes ignores the requested answer format and rules, even in full precision. When it fails, the failure mode is often not “the model does not know the answer.” It is “the model did not follow the benchmark’s answer format.” For example, this could be: instead of responding with “A”, the model will likely try to reason about the answer. In other words: too much reasoning text, not enough benchmark-compatible answering. We will revisit this example in a separate evaluation post.
Since this is already a baseline-model issue, we do not think MMLU is a clean way to compare quantized variants for this release.
Now, let’s look at the models we are releasing.
Next-Token Prediction (NTP)
First, let’s look at the standard single-token prediction models. For most devices, the message is simple: Pick ByteShape model 5 if it fits. If not, look at models 3 and 2.
You should get a strong quality-speed trade-off, and the recommendation is fairly consistent across the hardware we tested.
GPUs
Compared with some of our previous releases, GPU model selection is unusually straightforward here. The ordering is mostly consistent across devices. Memory decides which models are in the race, and once a model fits, the larger ByteShape variant is usually the best choice.
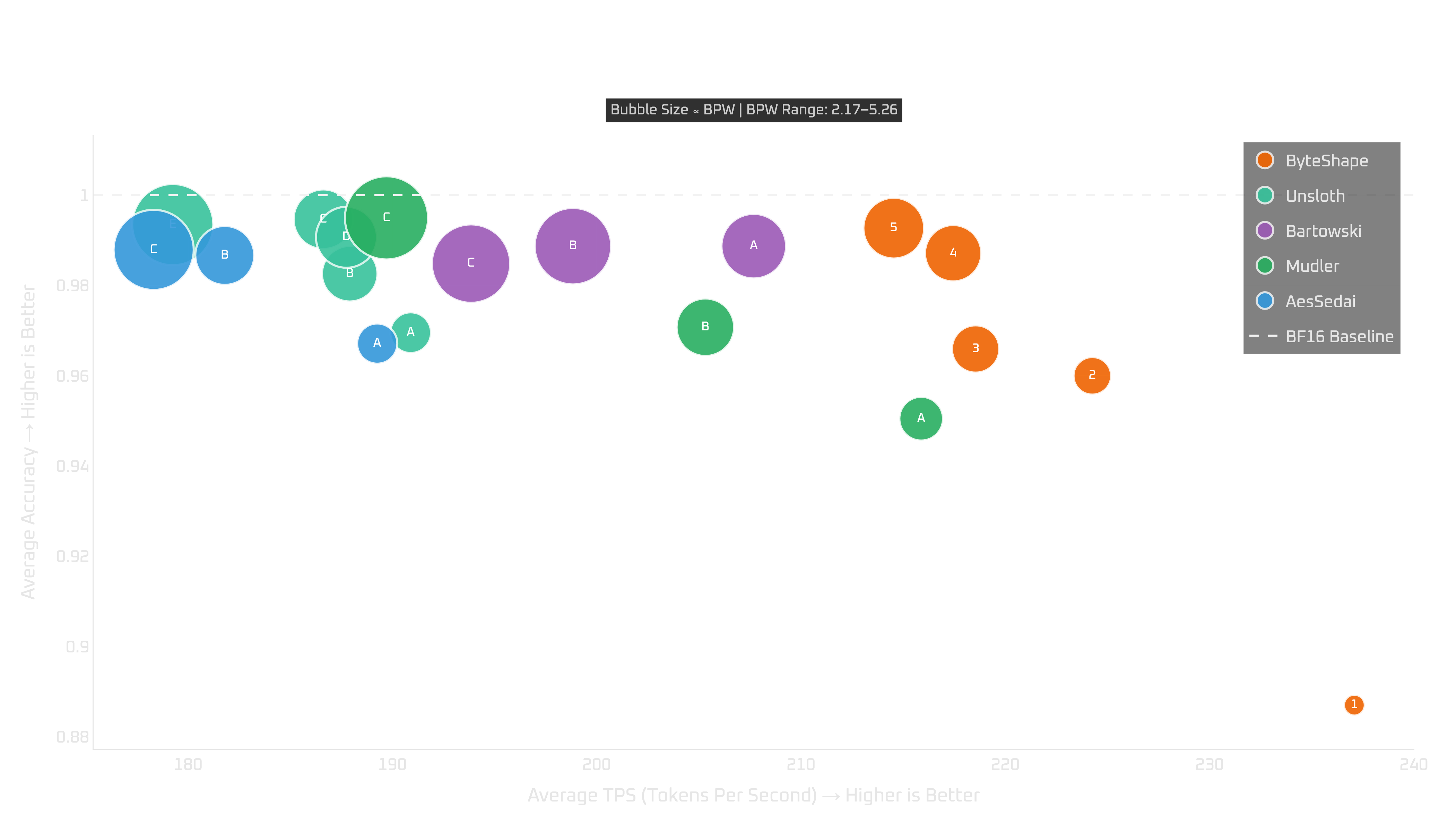
24+GB GPUs: RTX 4090, 5090, & Pro 6000
GPU-5 is our main recommendation. It reaches about 99% of the baseline quality while delivering strong token-generation and prompt-processing throughput. Across the 24+GB GPUs we tested, it gives the best overall quality-speed trade-off.
If you need more room for context, or if you want a bit more throughput, GPU-4 and GPU-3 can be reasonable fallbacks. But for most 24+GB GPU users, GPU-5 is the one to start with.
Show Legend
| # | Model | Acc | TPS | BPW |
|---|---|---|---|---|
| ByteShape | ||||
| GPU-1 | IQ2_S-2.17bpw | 0.8870 | 237.09 | 2.17 |
| GPU-2 | IQ3_S-3.00bpw | 0.9600 | 224.26 | 3.00 |
| GPU-3 | IQ3_S-3.48bpw | 0.9659 | 218.55 | 3.48 |
| GPU-4 | IQ4_XS-3.93bpw | 0.9871 | 217.45 | 3.93 |
| GPU-5 | IQ4_XS-4.15bpw | 0.9927 | 214.54 | 4.15 |
| Unsloth | ||||
| A | UD-IQ3_S | 0.9695 | 190.90 | 3.15 |
| B | UD-Q3_K_XL | 0.9826 | 187.91 | 3.89 |
| C | UD-IQ4_XS | 0.9946 | 186.62 | 4.09 |
| D | UD-IQ4_NL | 0.9907 | 187.75 | 4.16 |
| E | UD-Q4_K_XL | 0.9935 | 179.25 | 5.16 |
| Bartowski | ||||
| A | IQ4_XS | 0.9887 | 207.69 | 4.34 |
| B | Q4_K_M | 0.9887 | 198.84 | 4.93 |
| C | Q4_K_L | 0.9848 | 193.85 | 5.02 |
| Mudler | ||||
| A | APEX-I-Mini | 0.9505 | 215.88 | 3.30 |
| B | APEX-I-Compact | 0.9707 | 205.32 | 3.99 |
| C | APEX-I-Quality | 0.9950 | 189.71 | 5.26 |
| AesSedai | ||||
| A | IQ3_S | 0.9671 | 189.26 | 3.13 |
| B | IQ4_XS | 0.9866 | 181.80 | 4.06 |
| C | Q4_K_M | 0.9879 | 178.31 | 5.11 |
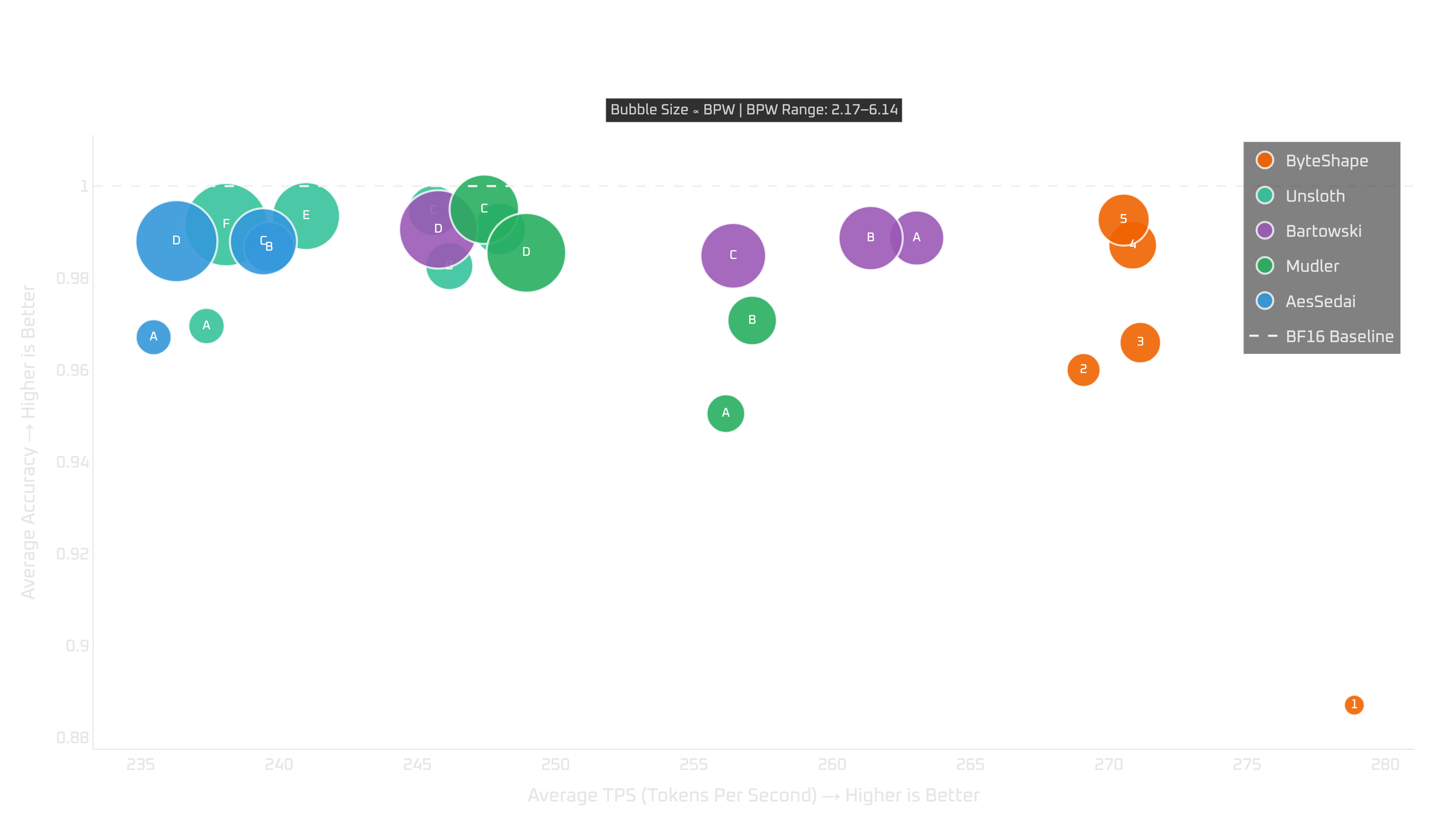
Show Legend
| # | Model | Acc | TPS | BPW |
|---|---|---|---|---|
| ByteShape | ||||
| GPU-1 | IQ2_S-2.17bpw | 0.8870 | 278.88 | 2.17 |
| GPU-2 | IQ3_S-3.00bpw | 0.9600 | 269.09 | 3.00 |
| GPU-3 | IQ3_S-3.48bpw | 0.9659 | 271.14 | 3.48 |
| GPU-4 | IQ4_XS-3.93bpw | 0.9871 | 270.86 | 3.93 |
| GPU-5 | IQ4_XS-4.15bpw | 0.9927 | 270.54 | 4.15 |
| Unsloth | ||||
| A | UD-IQ3_S | 0.9695 | 237.38 | 3.15 |
| B | UD-Q3_K_XL | 0.9826 | 246.16 | 3.89 |
| C | UD-IQ4_XS | 0.9946 | 245.59 | 4.09 |
| D | UD-IQ4_NL | 0.9907 | 247.98 | 4.16 |
| E | UD-Q4_K_XL | 0.9935 | 240.98 | 5.16 |
| F | UD-Q5_K_XL | 0.9916 | 238.09 | 6.14 |
| Bartowski | ||||
| A | IQ4_XS | 0.9887 | 263.06 | 4.34 |
| B | Q4_K_M | 0.9887 | 261.39 | 4.93 |
| C | Q4_K_L | 0.9848 | 256.42 | 5.02 |
| D | Q5_K_L | 0.9906 | 245.76 | 5.84 |
| Mudler | ||||
| A | APEX-I-Mini | 0.9505 | 256.15 | 3.30 |
| B | APEX-I-Compact | 0.9707 | 257.11 | 3.99 |
| C | APEX-I-Quality | 0.9950 | 247.42 | 5.26 |
| D | APEX-I-Balanced | 0.9855 | 248.94 | 5.91 |
| AesSedai | ||||
| A | IQ3_S | 0.9671 | 235.47 | 3.13 |
| B | IQ4_XS | 0.9866 | 239.64 | 4.06 |
| C | Q4_K_M | 0.9879 | 239.44 | 5.11 |
| D | Q5_K_M | 0.9880 | 236.29 | 6.06 |
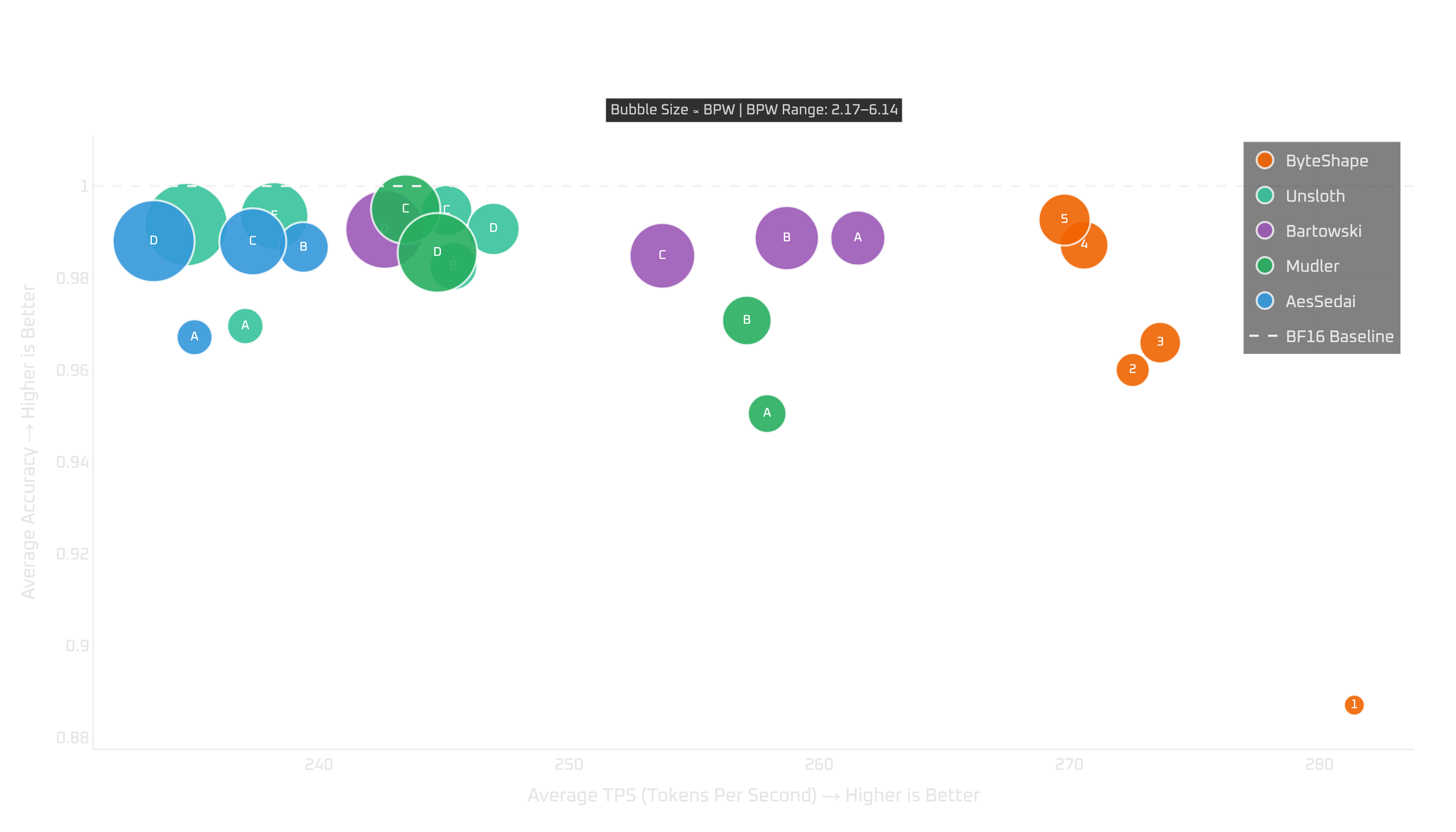
Show Legend
| # | Model | Acc | TPS | BPW |
|---|---|---|---|---|
| ByteShape | ||||
| GPU-1 | IQ2_S-2.17bpw | 0.8870 | 281.40 | 2.17 |
| GPU-2 | IQ3_S-3.00bpw | 0.9600 | 272.53 | 3.00 |
| GPU-3 | IQ3_S-3.48bpw | 0.9659 | 273.63 | 3.48 |
| GPU-4 | IQ4_XS-3.93bpw | 0.9871 | 270.59 | 3.93 |
| GPU-5 | IQ4_XS-4.15bpw | 0.9927 | 269.81 | 4.15 |
| Unsloth | ||||
| A | UD-IQ3_S | 0.9695 | 237.06 | 3.15 |
| B | UD-Q3_K_XL | 0.9826 | 245.37 | 3.89 |
| C | UD-IQ4_XS | 0.9946 | 245.11 | 4.09 |
| D | UD-IQ4_NL | 0.9907 | 246.98 | 4.16 |
| E | UD-Q4_K_XL | 0.9935 | 238.22 | 5.16 |
| F | UD-Q5_K_XL | 0.9916 | 234.69 | 6.14 |
| Bartowski | ||||
| A | IQ4_XS | 0.9887 | 261.54 | 4.34 |
| B | Q4_K_M | 0.9887 | 258.70 | 4.93 |
| C | Q4_K_L | 0.9848 | 253.73 | 5.02 |
| D | Q5_K_L | 0.9906 | 242.63 | 5.84 |
| Mudler | ||||
| A | APEX-I-Mini | 0.9505 | 257.92 | 3.30 |
| B | APEX-I-Compact | 0.9707 | 257.11 | 3.99 |
| C | APEX-I-Quality | 0.9950 | 243.47 | 5.26 |
| D | APEX-I-Balanced | 0.9855 | 244.74 | 5.91 |
| AesSedai | ||||
| A | IQ3_S | 0.9671 | 235.03 | 3.13 |
| B | IQ4_XS | 0.9866 | 239.38 | 4.06 |
| C | Q4_K_M | 0.9879 | 237.35 | 5.11 |
| D | Q5_K_M | 0.9880 | 233.39 | 6.06 |
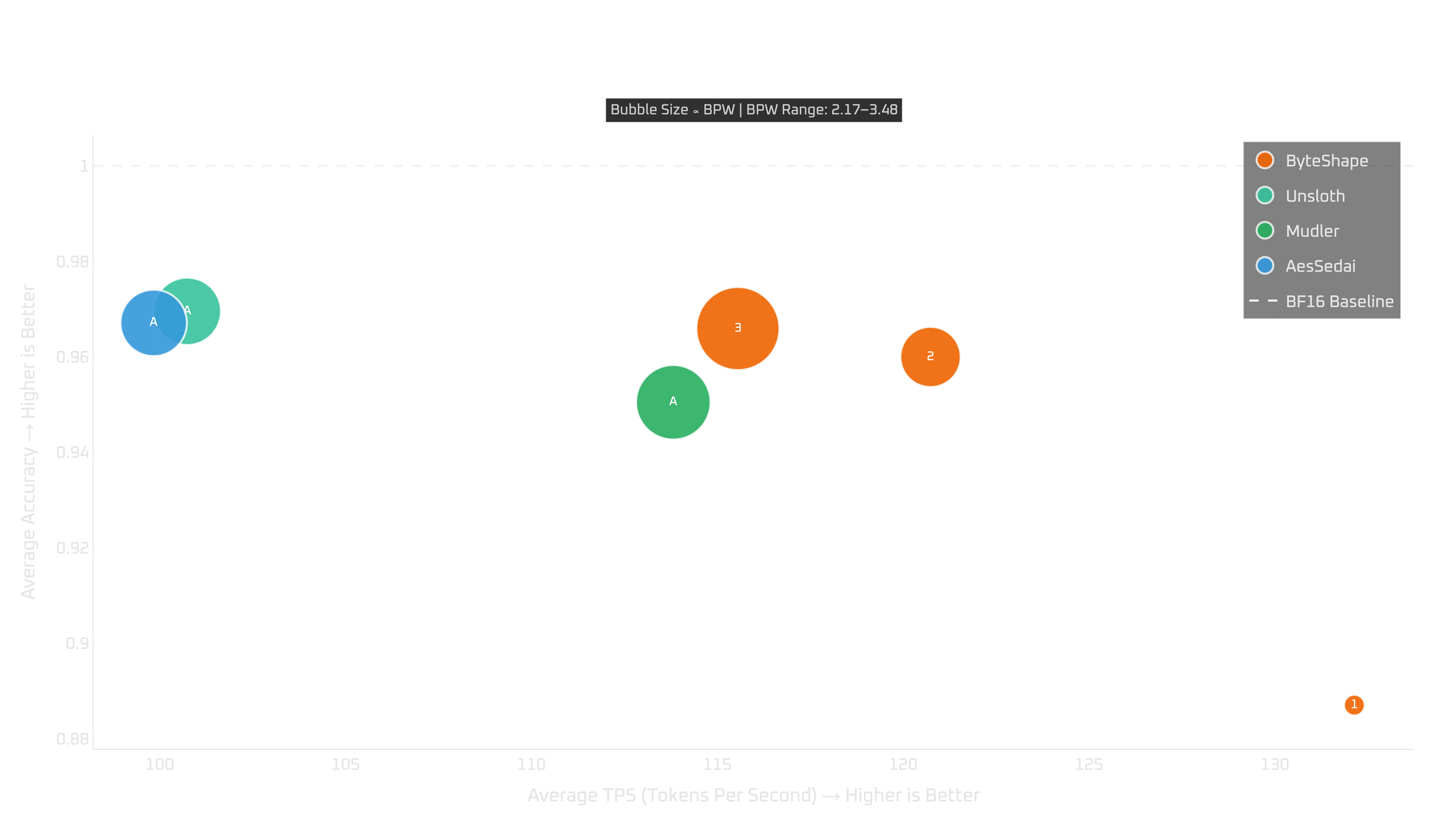
16GB GPUs: RTX 4080 & 5060 Ti
On 16GB GPUs, GPU-5 does not fit, so the recommendation has to change.
For NTP, GPU-3 is the most obvious choice. It gives the best practical balance of quality and throughput among the models that fit.
Here, we see the more familiar trade-off curve: you can trade some quality for more token-generation throughput by choosing a smaller model. Prompt processing is less predictable and does not follow the same clean relationship, but the ByteShape models remain strong across the tested devices.
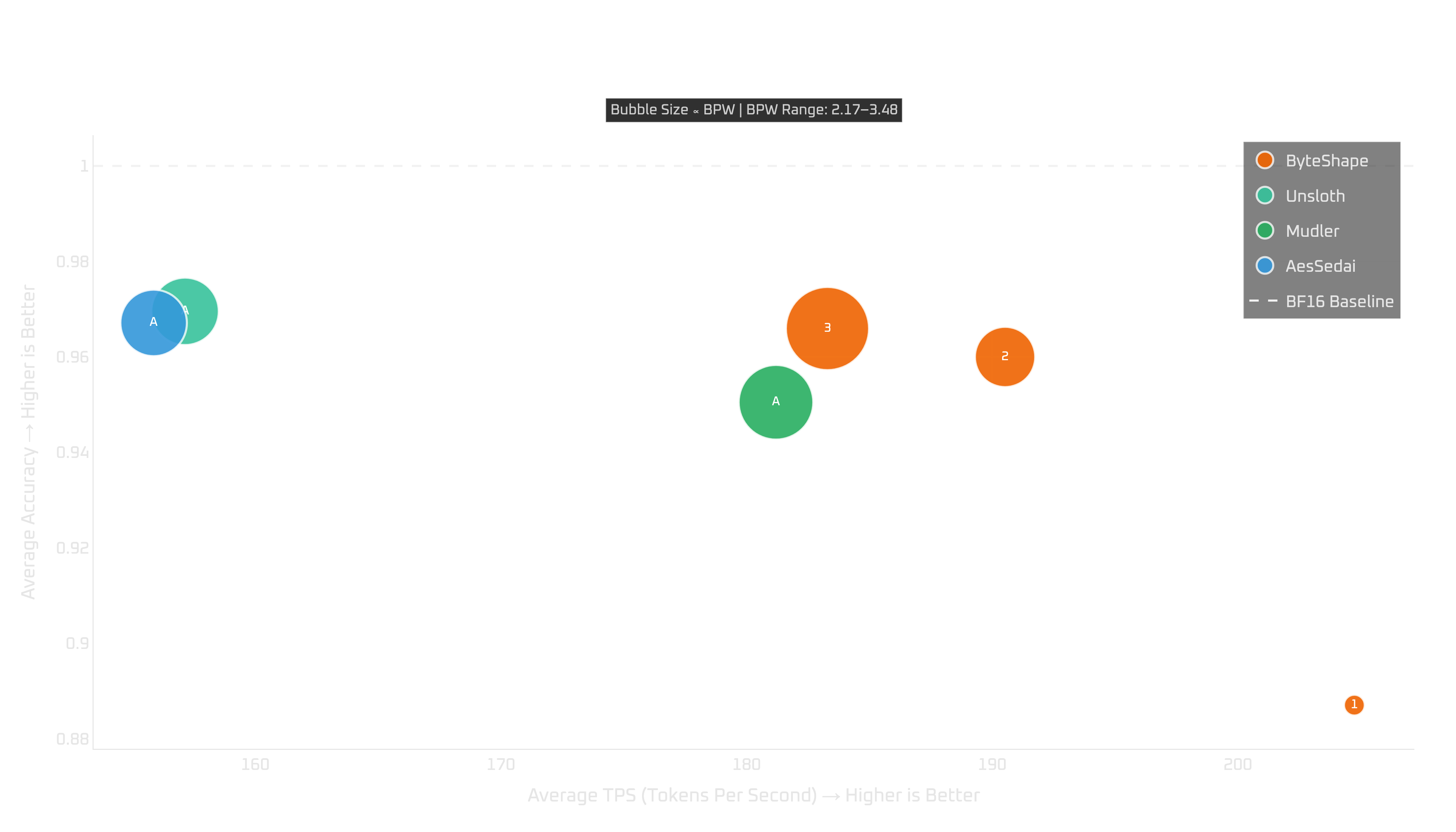
Show Legend
| # | Model | Acc | TPS | BPW |
|---|---|---|---|---|
| ByteShape | ||||
| GPU-1 | IQ2_S-2.17bpw | 0.8870 | 204.74 | 2.17 |
| GPU-2 | IQ3_S-3.00bpw | 0.9600 | 190.52 | 3.00 |
| GPU-3 | IQ3_S-3.48bpw | 0.9659 | 183.29 | 3.48 |
| Unsloth | ||||
| A | UD-IQ3_S | 0.9695 | 157.14 | 3.15 |
| Mudler | ||||
| A | APEX-I-Mini | 0.9505 | 181.20 | 3.30 |
| AesSedai | ||||
| A | IQ3_S | 0.9671 | 155.86 | 3.13 |
Show Legend
| # | Model | Acc | TPS | BPW |
|---|---|---|---|---|
| ByteShape | ||||
| GPU-1 | IQ2_S-2.17bpw | 0.8870 | 132.14 | 2.17 |
| GPU-2 | IQ3_S-3.00bpw | 0.9600 | 120.73 | 3.00 |
| GPU-3 | IQ3_S-3.48bpw | 0.9659 | 115.55 | 3.48 |
| Unsloth | ||||
| A | UD-IQ3_S | 0.9695 | 100.74 | 3.15 |
| Mudler | ||||
| A | APEX-I-Mini | 0.9505 | 113.81 | 3.30 |
| AesSedai | ||||
| A | IQ3_S | 0.9671 | 99.84 | 3.13 |
CPUs
CPU inference shows a different pattern.
For token generation, we see a fairly clean trade-off curve: smaller models are faster, but quality drops. Balancing the two is essential.
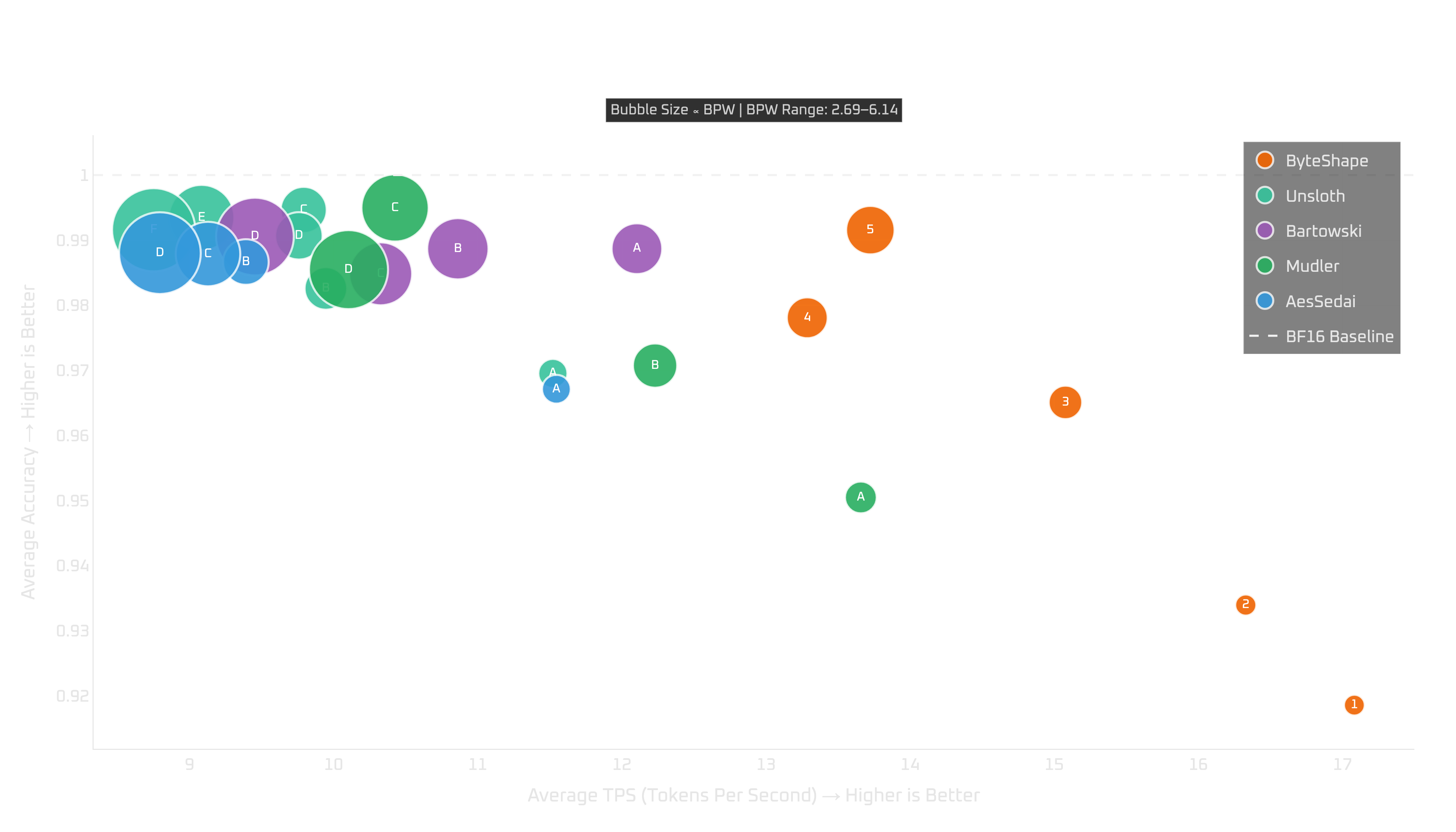
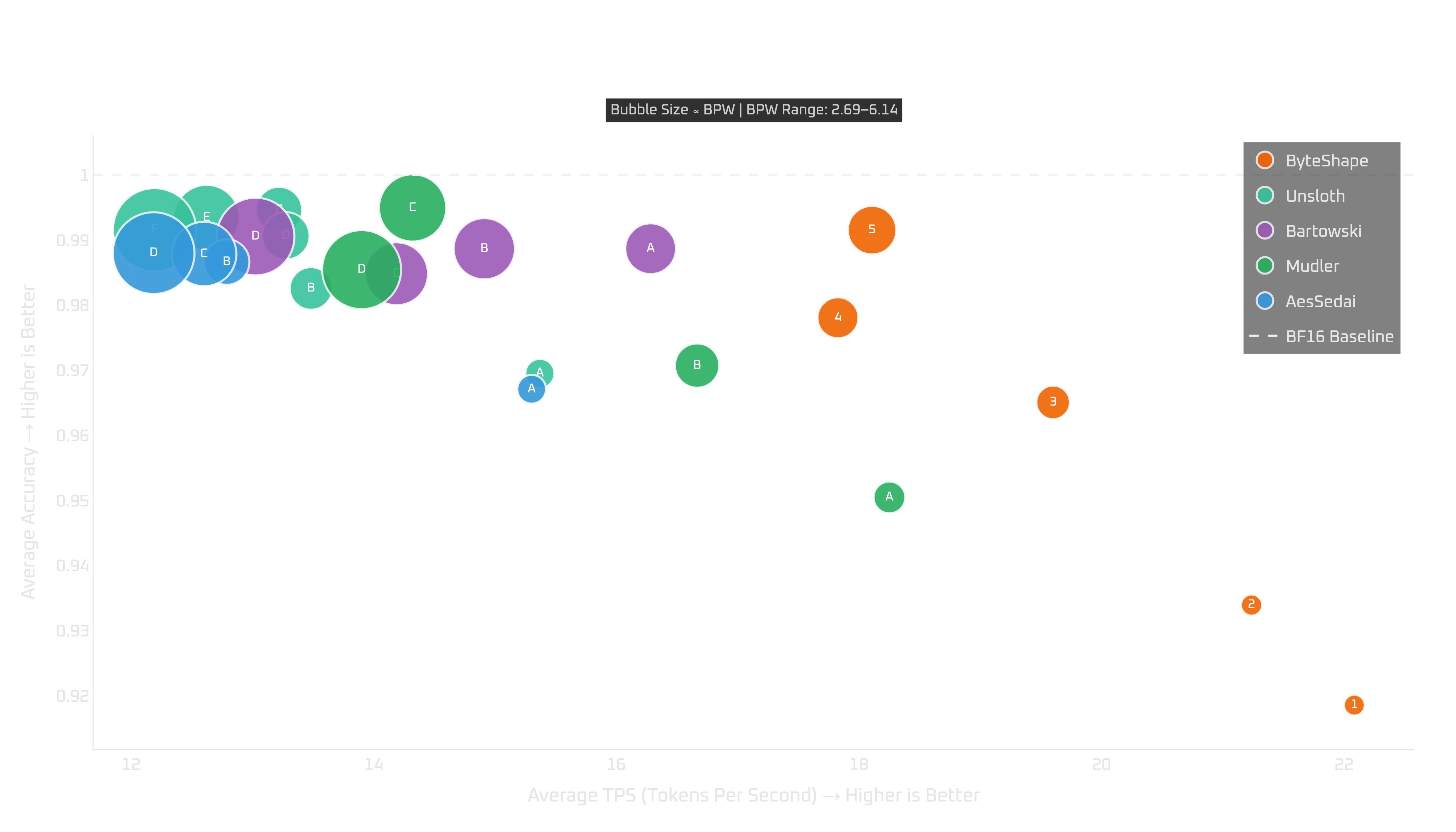
High-memory CPU setups: i7, Ultra 7 & Ryzen 9
When memory is not the main constraint, CPU-5 is the strongest default choice.
You can choose a smaller model for more token-generation throughput, but the trade-off is not free. You give up quality, and in our measurements prompt processing may also get worse. Unless your workload specifically benefits from the smaller variants, CPU-5 is likely the better starting point.
Show Legend
| # | Model | Acc | TPS | BPW |
|---|---|---|---|---|
| ByteShape | ||||
| CPU-1 | Q3_K_S-2.69bpw | 0.9186 | 17.08 | 2.69 |
| CPU-2 | Q3_K_S-2.71bpw | 0.9339 | 16.33 | 2.71 |
| CPU-3 | Q3_K_S-3.39bpw | 0.9651 | 15.08 | 3.39 |
| CPU-4 | Q4_K_S-3.80bpw | 0.9781 | 13.29 | 3.80 |
| CPU-5 | Q4_K_S-4.22bpw | 0.9915 | 13.72 | 4.22 |
| Unsloth | ||||
| A | UD-IQ3_S | 0.9695 | 11.52 | 3.15 |
| B | UD-Q3_K_XL | 0.9826 | 9.95 | 3.89 |
| C | UD-IQ4_XS | 0.9946 | 9.79 | 4.09 |
| D | UD-IQ4_NL | 0.9907 | 9.76 | 4.16 |
| E | UD-Q4_K_XL | 0.9935 | 9.08 | 5.16 |
| F | UD-Q5_K_XL | 0.9916 | 8.75 | 6.14 |
| Bartowski | ||||
| A | IQ4_XS | 0.9887 | 12.10 | 4.34 |
| B | Q4_K_M | 0.9887 | 10.86 | 4.93 |
| C | Q4_K_L | 0.9848 | 10.33 | 5.02 |
| D | Q5_K_L | 0.9906 | 9.45 | 5.84 |
| Mudler | ||||
| A | APEX-I-Mini | 0.9505 | 13.66 | 3.30 |
| B | APEX-I-Compact | 0.9707 | 12.23 | 3.99 |
| C | APEX-I-Quality | 0.9950 | 10.43 | 5.26 |
| D | APEX-I-Balanced | 0.9855 | 10.10 | 5.91 |
| AesSedai | ||||
| A | IQ3_S | 0.9671 | 11.55 | 3.13 |
| B | IQ4_XS | 0.9866 | 9.39 | 4.06 |
| C | Q4_K_M | 0.9879 | 9.13 | 5.11 |
| D | Q5_K_M | 0.9880 | 8.79 | 6.06 |
Show Legend
| # | Model | Acc | TPS | BPW |
|---|---|---|---|---|
| ByteShape | ||||
| CPU-1 | Q3_K_S-2.69bpw | 0.9186 | 22.08 | 2.69 |
| CPU-2 | Q3_K_S-2.71bpw | 0.9339 | 21.24 | 2.71 |
| CPU-3 | Q3_K_S-3.39bpw | 0.9651 | 19.60 | 3.39 |
| CPU-4 | Q4_K_S-3.80bpw | 0.9781 | 17.83 | 3.80 |
| CPU-5 | Q4_K_S-4.22bpw | 0.9915 | 18.11 | 4.22 |
| Unsloth | ||||
| A | UD-IQ3_S | 0.9695 | 15.37 | 3.15 |
| B | UD-Q3_K_XL | 0.9826 | 13.48 | 3.89 |
| C | UD-IQ4_XS | 0.9946 | 13.22 | 4.09 |
| D | UD-IQ4_NL | 0.9907 | 13.28 | 4.16 |
| E | UD-Q4_K_XL | 0.9935 | 12.62 | 5.16 |
| F | UD-Q5_K_XL | 0.9916 | 12.19 | 6.14 |
| Bartowski | ||||
| A | IQ4_XS | 0.9887 | 16.28 | 4.34 |
| B | Q4_K_M | 0.9887 | 14.91 | 4.93 |
| C | Q4_K_L | 0.9848 | 14.19 | 5.02 |
| D | Q5_K_L | 0.9906 | 13.03 | 5.84 |
| Mudler | ||||
| A | APEX-I-Mini | 0.9505 | 18.25 | 3.30 |
| B | APEX-I-Compact | 0.9707 | 16.67 | 3.99 |
| C | APEX-I-Quality | 0.9950 | 14.32 | 5.26 |
| D | APEX-I-Balanced | 0.9855 | 13.90 | 5.91 |
| AesSedai | ||||
| A | IQ3_S | 0.9671 | 15.30 | 3.13 |
| B | IQ4_XS | 0.9866 | 12.79 | 4.06 |
| C | Q4_K_M | 0.9879 | 12.60 | 5.11 |
| D | Q5_K_M | 0.9880 | 12.19 | 6.06 |
Show Legend
| # | Model | Acc | TPS | BPW |
|---|---|---|---|---|
| ByteShape | ||||
| CPU-1 | Q3_K_S-2.69bpw | 0.9186 | 19.85 | 2.69 |
| CPU-2 | Q3_K_S-2.71bpw | 0.9339 | 18.09 | 2.71 |
| CPU-3 | Q3_K_S-3.39bpw | 0.9651 | 16.75 | 3.39 |
| CPU-4 | Q4_K_S-3.80bpw | 0.9781 | 15.72 | 3.80 |
| CPU-5 | Q4_K_S-4.22bpw | 0.9915 | 15.47 | 4.22 |
| Unsloth | ||||
| A | UD-IQ3_S | 0.9695 | 14.85 | 3.15 |
| B | UD-Q3_K_XL | 0.9826 | 12.04 | 3.89 |
| C | UD-IQ4_XS | 0.9946 | 11.83 | 4.09 |
| D | UD-IQ4_NL | 0.9907 | 10.15 | 4.16 |
| E | UD-Q4_K_XL | 0.9935 | 11.25 | 5.16 |
| F | UD-Q5_K_XL | 0.9916 | 11.89 | 6.14 |
| Bartowski | ||||
| A | IQ4_XS | 0.9887 | 15.04 | 4.34 |
| B | Q4_K_M | 0.9887 | 12.72 | 4.93 |
| C | Q4_K_L | 0.9848 | 11.90 | 5.02 |
| D | Q5_K_L | 0.9906 | 12.20 | 5.84 |
| Mudler | ||||
| A | APEX-I-Mini | 0.9505 | 14.94 | 3.30 |
| B | APEX-I-Compact | 0.9707 | 14.41 | 3.99 |
| C | APEX-I-Quality | 0.9950 | 14.60 | 5.26 |
| D | APEX-I-Balanced | 0.9855 | 13.97 | 5.91 |
| AesSedai | ||||
| A | IQ3_S | 0.9671 | 13.89 | 3.13 |
| B | IQ4_XS | 0.9866 | 10.82 | 4.06 |
| C | Q4_K_M | 0.9879 | 11.75 | 5.11 |
| D | Q5_K_M | 0.9880 | 12.16 | 6.06 |
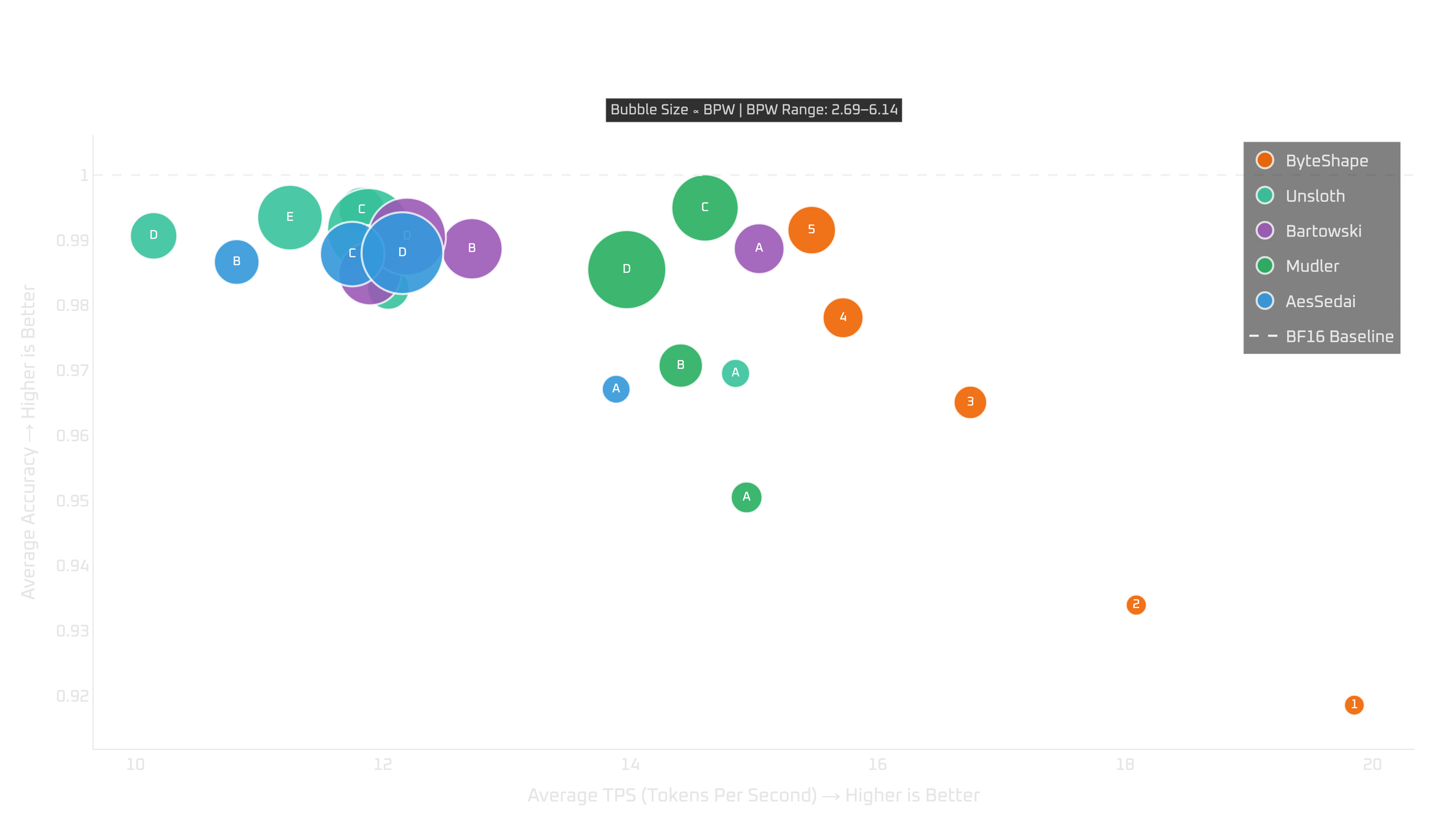
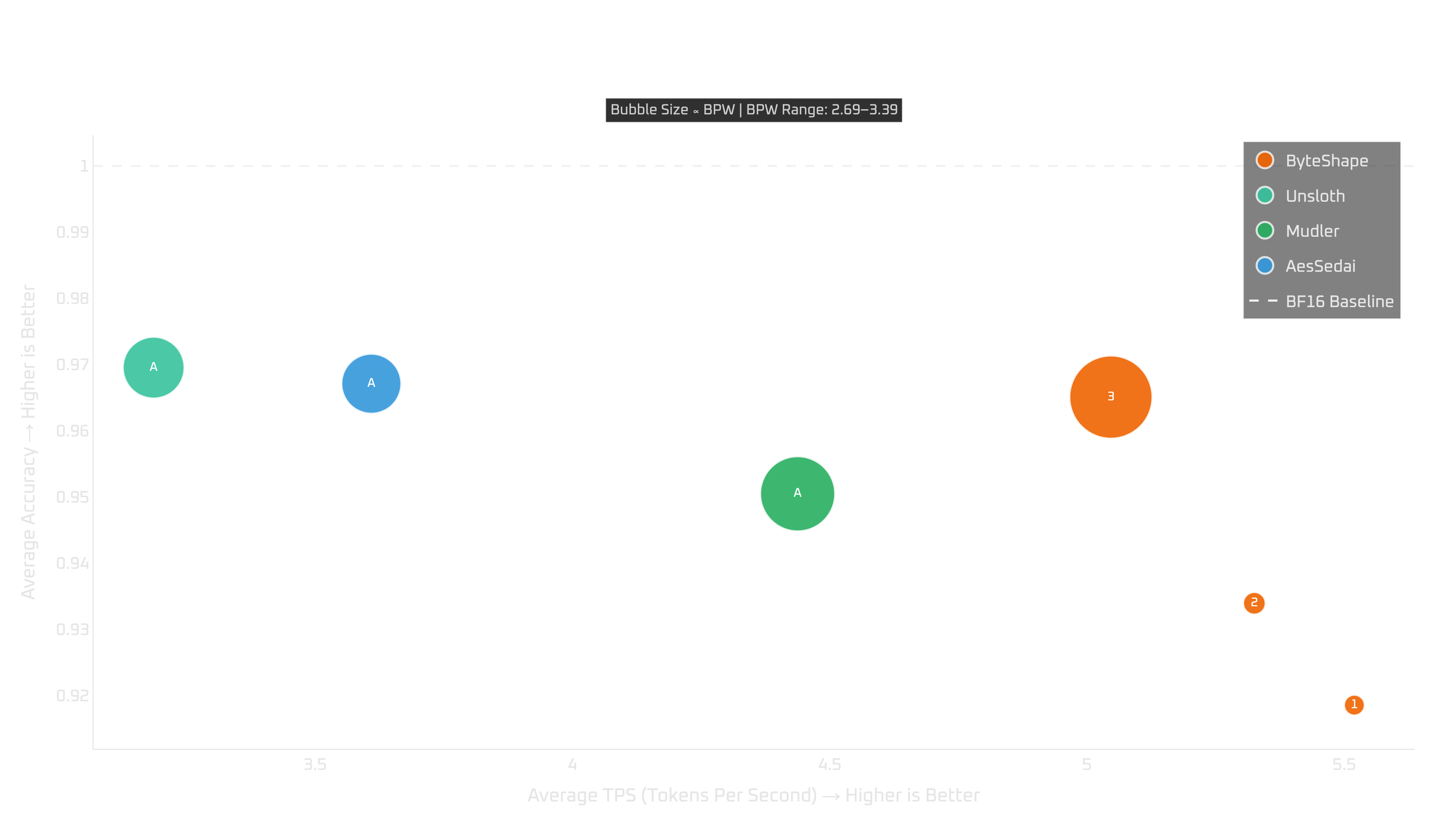
Memory-limited CPU setup: Raspberry Pi 5
On a 16GB Raspberry Pi 5, the choice gets more interesting.
CPU-3 gives the best quality among the practical options, with “near” real-time generation. Moving down to CPU-2 improves both prompt-processing and token-generation throughput by roughly 10%, but it comes at a meaningful quality cost. In our measurements, the error rate roughly doubles.
So the recommendation depends on what you care about:
- choose
CPU-3if you want the best quality that fits, - choose
CPU-2if you are willing to trade quality for a modest speed increase.
Show Legend
| # | Model | Acc | TPS | BPW |
|---|---|---|---|---|
| ByteShape | ||||
| CPU-1 | Q3_K_S-2.69bpw | 0.9186 | 5.52 | 2.69 |
| CPU-2 | Q3_K_S-2.71bpw | 0.9339 | 5.33 | 2.71 |
| CPU-3 | Q3_K_S-3.39bpw | 0.9651 | 5.05 | 3.39 |
| Unsloth | ||||
| A | UD-IQ3_S | 0.9695 | 3.19 | 3.15 |
| Mudler | ||||
| A | APEX-I-Mini | 0.9505 | 4.44 | 3.30 |
| AesSedai | ||||
| A | IQ3_S | 0.9671 | 3.61 | 3.13 |
Multi-Token Prediction (MTP)
We are also releasing MTP models alongside the standard NTP models.
MTP gives a token-generation throughput boost by predicting multiple future tokens. Prediction is still a guess. MTP helps when those guesses are correct often enough to outweigh the overhead of making and validating them. Whether this results in a boost or not depends on the overhead for making and validating the prediction, and on how frequently the prediction proves correct. In our tests, that boost is real on GPUs, and the quality impact is small enough that the MTP models are worth considering.
The trade-off is memory and prompt processing. MTP increases the runtime footprint, so a model that fits comfortably in NTP mode may not fit in MTP mode with the same context length. Prompt processing also becomes less attractive, especially on CPUs.
So the short version is:
MTP is useful for GPU generation speed. Be careful with memory. Be very careful with prompt processing.
MTP on GPUs
On GPUs, MTP makes sense. Across our tested devices, it gives roughly 20–40% higher token-generation throughput.
For most GPU users, the recommendation remains similar to NTP: choose the largest ByteShape model that fits your memory and context needs.
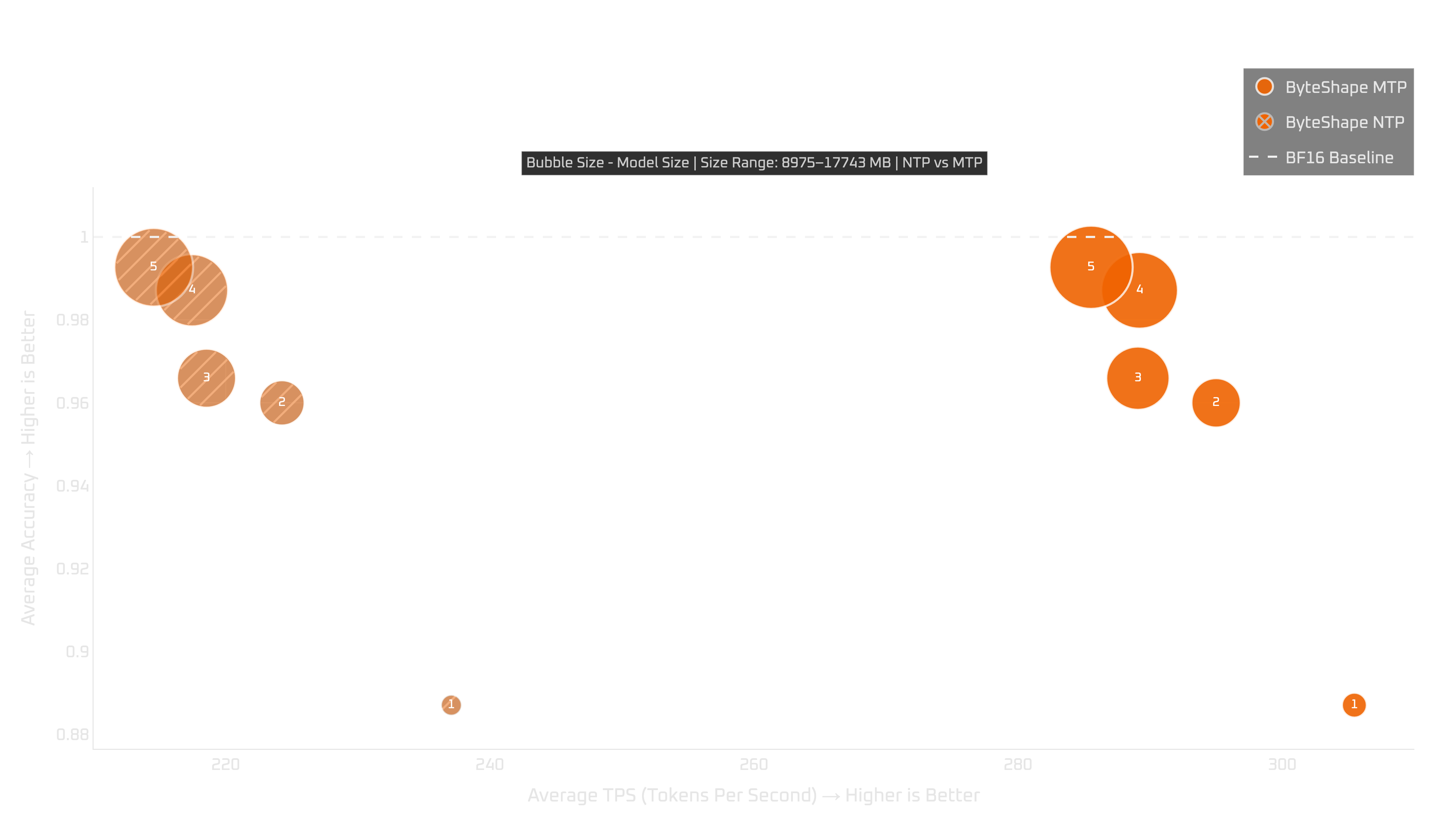
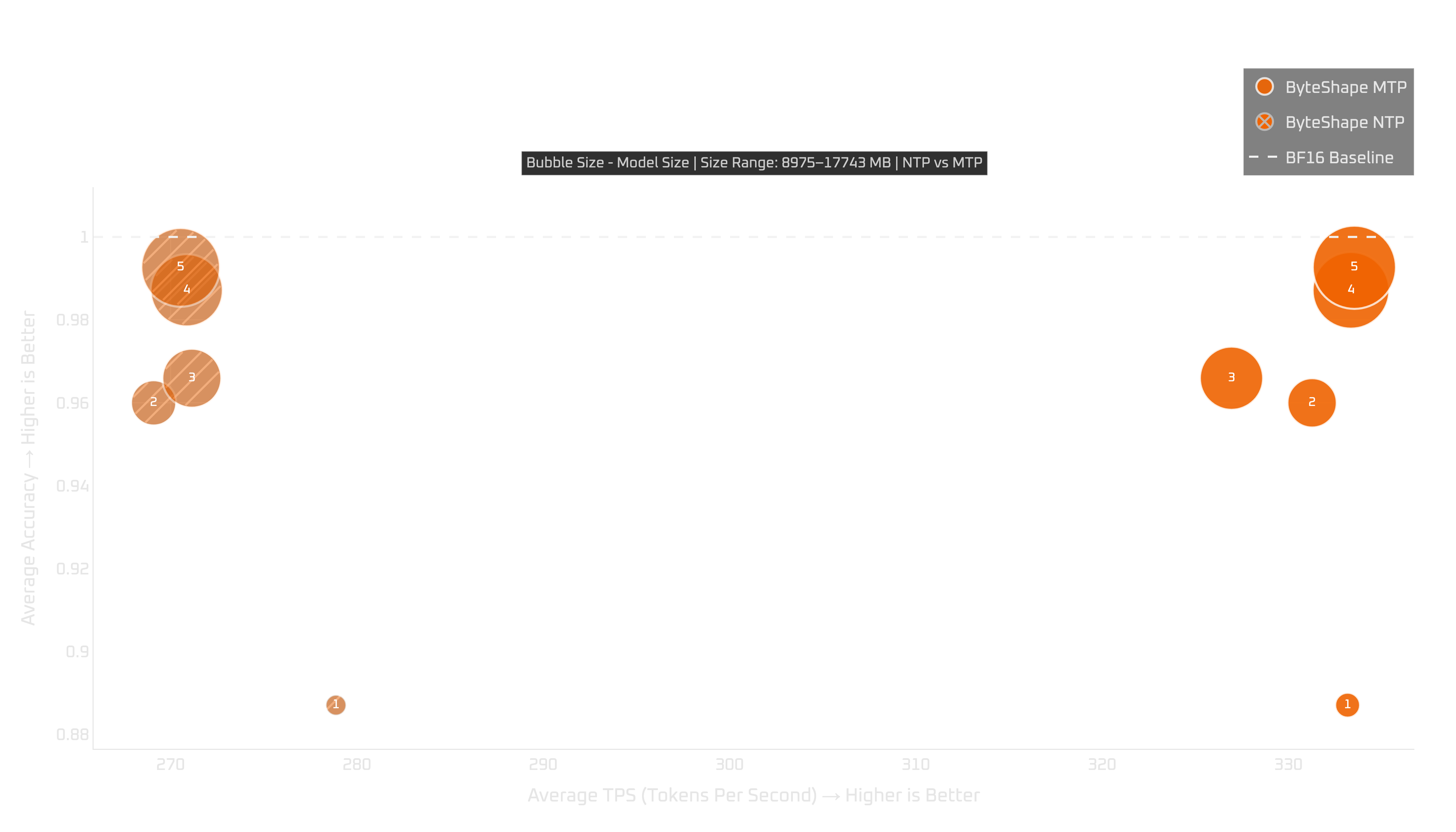
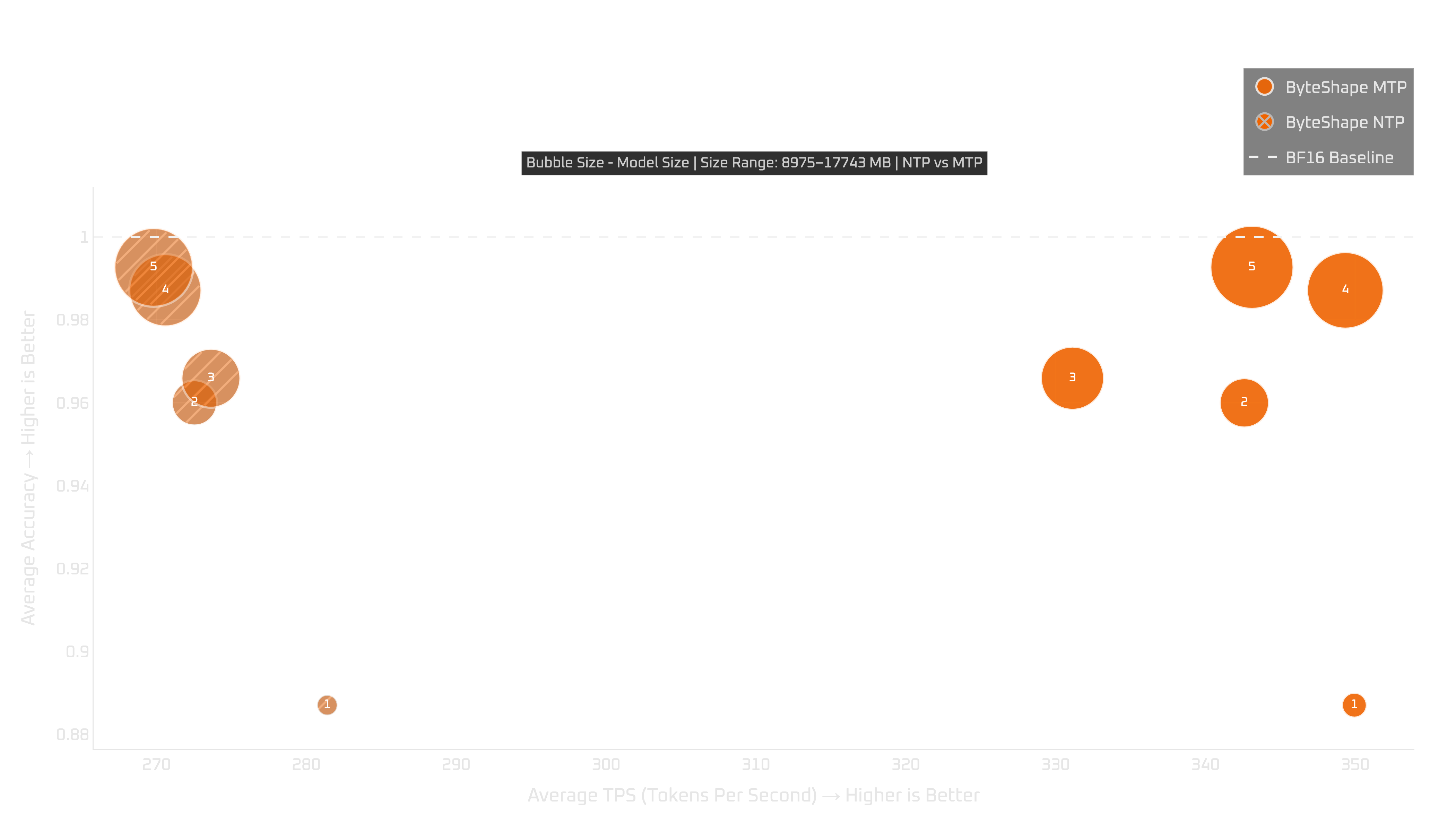
24+GB GPUs: RTX 4090, 5090, & Pro 6000
On 24+GB GPUs, the recommendation is mostly consistent with NTP: use MTP-GPU-5.
It gives the strongest overall quality-speed trade-off among the MTP models that fit.
If you want more throughput and can accept some trade-off, MTP-GPU-4 is also worth considering on the RTX 4090 and RTX Pro 6000. In those runs, MTP-GPU-4 gets a larger MTP boost than MTP-GPU-5.
The RTX 5090 result is less clean: MTP-GPU-4 underperforms in both quality and throughput compared with what we see on the other 24+GB GPUs. Because of that, we do not recommend it for the RTX 5090.
We also do not recommend MTP-GPU-3 on the 24+GB GPUs we tested. It has lower quality and lower throughput than the stronger options, so there is not much reason to choose it unless you have a very specific memory constraint.
Show Legend
| # | Model | Acc | TPS | BPW |
|---|---|---|---|---|
| ByteShape MTP | ||||
| MTP-GPU-1 | IQ2_S-2.25bpw | 0.8870 | 305.47 | 2.25 |
| MTP-GPU-2 | IQ3_S-3.06bpw | 0.9600 | 295.00 | 3.06 |
| MTP-GPU-3 | IQ4_XS-3.53bpw | 0.9659 | 289.08 | 3.53 |
| MTP-GPU-4 | IQ4_XS-3.97bpw | 0.9871 | 289.20 | 3.97 |
| MTP-GPU-5 | IQ4_XS-4.19bpw | 0.9927 | 285.53 | 4.19 |
| ByteShape NTP (for comparison) | ||||
| GPU-1 | IQ2_S-2.17bpw | 0.8870 | 237.09 | 2.17 |
| GPU-2 | IQ3_S-3.00bpw | 0.9600 | 224.26 | 3.00 |
| GPU-3 | IQ3_S-3.48bpw | 0.9659 | 218.55 | 3.48 |
| GPU-4 | IQ4_XS-3.93bpw | 0.9871 | 217.45 | 3.93 |
| GPU-5 | IQ4_XS-4.15bpw | 0.9927 | 214.54 | 4.15 |
Show Legend
| # | Model | Acc | TPS | BPW |
|---|---|---|---|---|
| ByteShape MTP | ||||
| MTP-GPU-1 | IQ2_S-2.25bpw | 0.8870 | 333.18 | 2.25 |
| MTP-GPU-2 | IQ3_S-3.06bpw | 0.9600 | 331.28 | 3.06 |
| MTP-GPU-3 | IQ4_XS-3.53bpw | 0.9659 | 326.95 | 3.53 |
| MTP-GPU-4 | IQ4_XS-3.97bpw | 0.9871 | 333.36 | 3.97 |
| MTP-GPU-5 | IQ4_XS-4.19bpw | 0.9927 | 333.55 | 4.19 |
| ByteShape NTP (for comparison) | ||||
| GPU-1 | IQ2_S-2.17bpw | 0.8870 | 278.88 | 2.17 |
| GPU-2 | IQ3_S-3.00bpw | 0.9600 | 269.09 | 3.00 |
| GPU-3 | IQ3_S-3.48bpw | 0.9659 | 271.14 | 3.48 |
| GPU-4 | IQ4_XS-3.93bpw | 0.9871 | 270.86 | 3.93 |
| GPU-5 | IQ4_XS-4.15bpw | 0.9927 | 270.54 | 4.15 |
Show Legend
| # | Model | Acc | TPS | BPW |
|---|---|---|---|---|
| ByteShape MTP | ||||
| MTP-GPU-1 | IQ2_S-2.25bpw | 0.8870 | 349.94 | 2.25 |
| MTP-GPU-2 | IQ3_S-3.06bpw | 0.9600 | 342.60 | 3.06 |
| MTP-GPU-3 | IQ4_XS-3.53bpw | 0.9659 | 331.13 | 3.53 |
| MTP-GPU-4 | IQ4_XS-3.97bpw | 0.9871 | 349.34 | 3.97 |
| MTP-GPU-5 | IQ4_XS-4.19bpw | 0.9927 | 343.11 | 4.19 |
| ByteShape NTP (for comparison) | ||||
| GPU-1 | IQ2_S-2.17bpw | 0.8870 | 281.40 | 2.17 |
| GPU-2 | IQ3_S-3.00bpw | 0.9600 | 272.53 | 3.00 |
| GPU-3 | IQ3_S-3.48bpw | 0.9659 | 273.63 | 3.48 |
| GPU-4 | IQ4_XS-3.93bpw | 0.9871 | 270.59 | 3.93 |
| GPU-5 | IQ4_XS-4.15bpw | 0.9927 | 269.81 | 4.15 |
16GB GPUs: RTX 4080 & 5060 Ti
This is where the extra MTP memory footprint matters. With a reasonable context length, MTP-GPU-3 does not fit in 16GB, so our practical recommendation is MTP-GPU-2. It still reaches about 96% of baseline quality, while improving token-generation throughput by roughly 32–42% in our measurements. That makes it a good option for users who care about generation speed and are working within a 16GB memory budget.
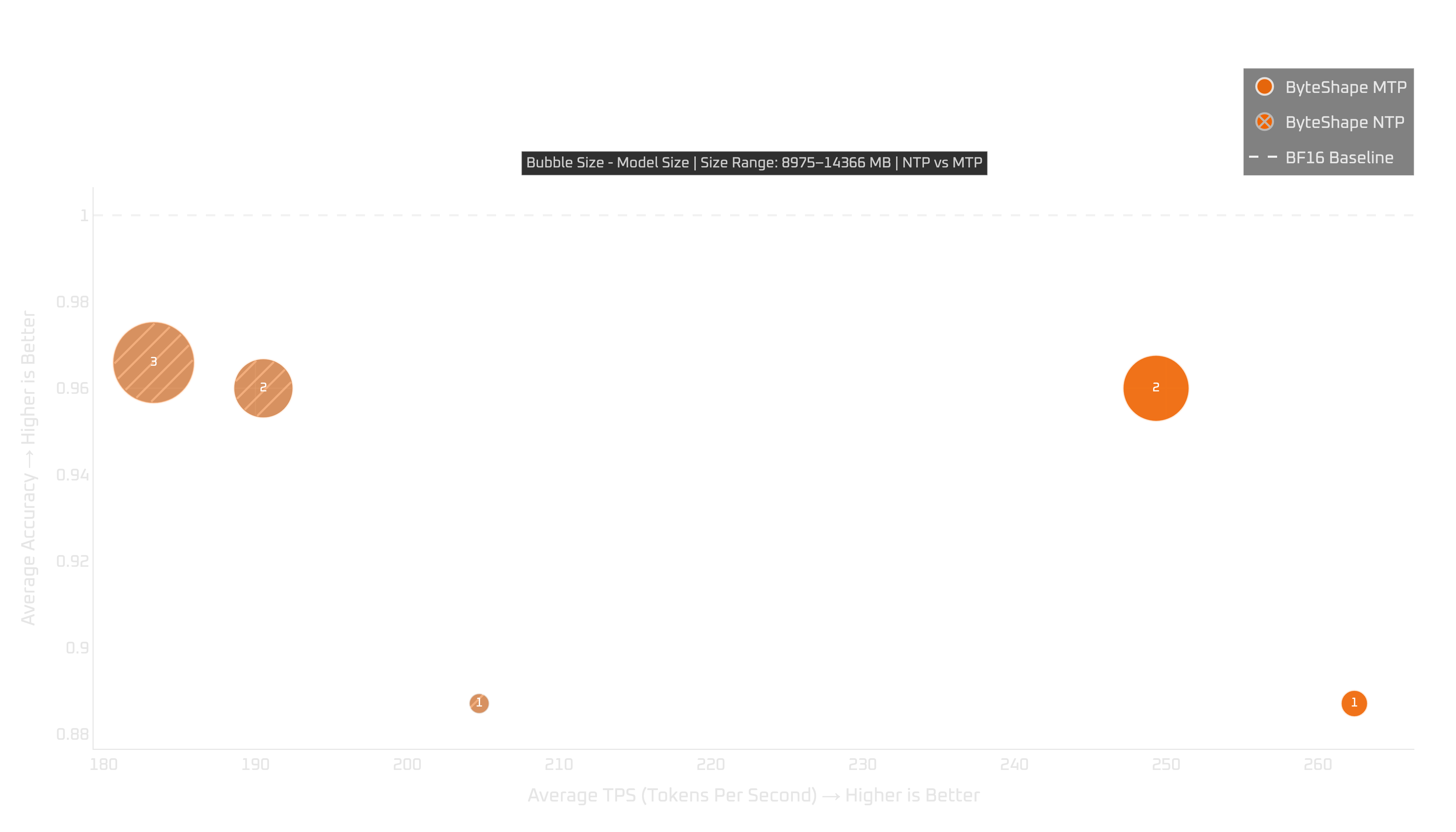
Show Legend
| # | Model | Acc | TPS | BPW |
|---|---|---|---|---|
| ByteShape MTP | ||||
| MTP-GPU-1 | IQ2_S-2.25bpw | 0.8870 | 262.39 | 2.25 |
| MTP-GPU-2 | IQ3_S-3.06bpw | 0.9600 | 249.33 | 3.06 |
| ByteShape NTP (for comparison) | ||||
| GPU-1 | IQ2_S-2.17bpw | 0.8870 | 204.74 | 2.17 |
| GPU-2 | IQ3_S-3.00bpw | 0.9600 | 190.52 | 3.00 |
| GPU-3 | IQ3_S-3.48bpw | 0.9659 | 183.29 | 3.48 |
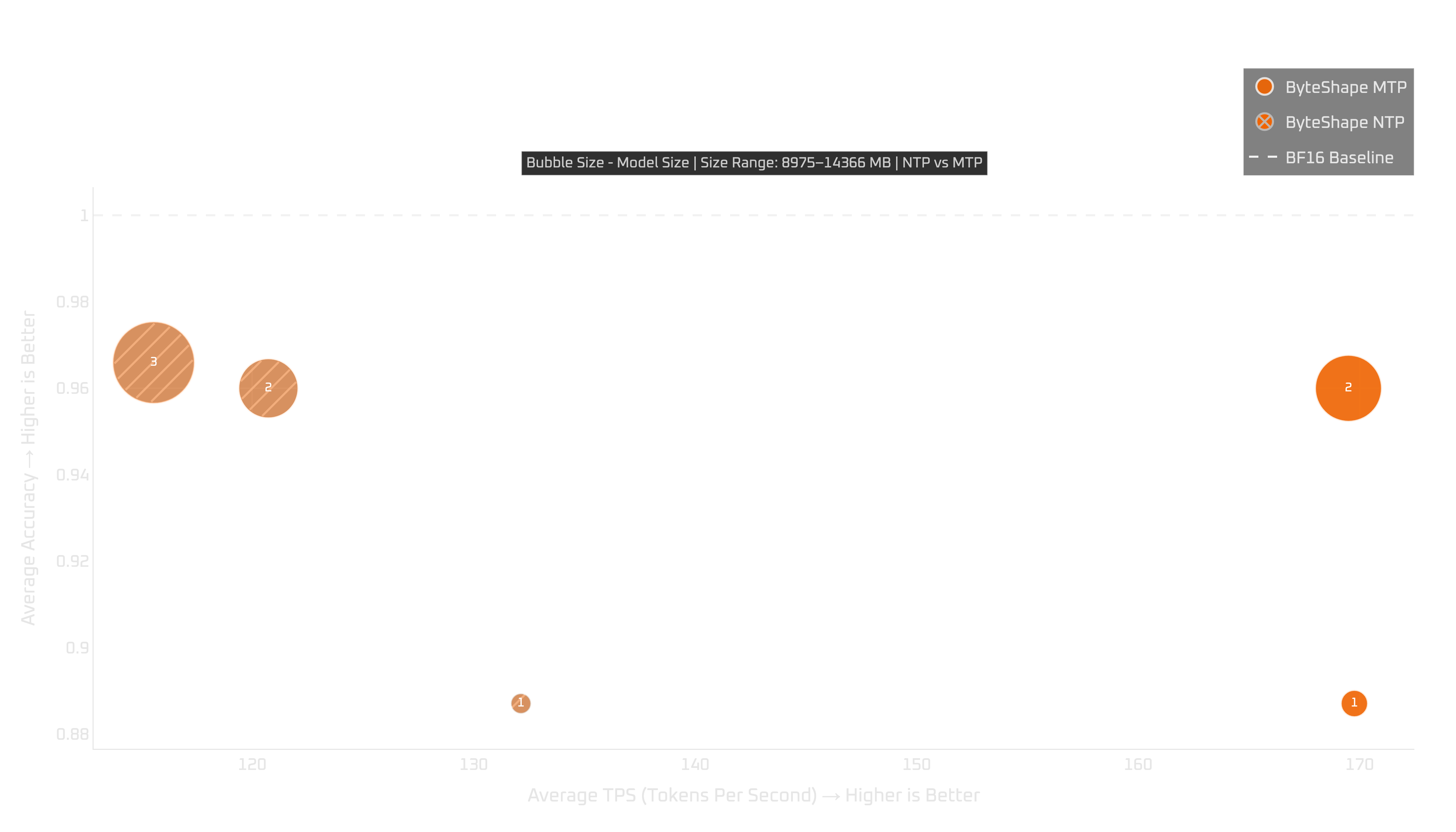
Show Legend
| # | Model | Acc | TPS | BPW |
|---|---|---|---|---|
| ByteShape MTP | ||||
| MTP-GPU-1 | IQ2_S-2.25bpw | 0.8870 | 169.76 | 2.25 |
| MTP-GPU-2 | IQ3_S-3.06bpw | 0.9600 | 169.50 | 3.06 |
| ByteShape NTP (for comparison) | ||||
| GPU-1 | IQ2_S-2.17bpw | 0.8870 | 132.14 | 2.17 |
| GPU-2 | IQ3_S-3.00bpw | 0.9600 | 120.73 | 3.00 |
| GPU-3 | IQ3_S-3.48bpw | 0.9659 | 115.55 | 3.48 |
MTP on CPUs
For now, we do not recommend MTP for CPU inference. CPU inference is already heavily constrained by prompt processing. MTP improves token generation, but it adds extra compute load and makes the prompt-processing side less attractive. The trade-off is not worth it.
If that changes in future backends or hardware, we will revisit CPU MTP releases. For now, our CPU recommendation remains NTP.
Conclusion
This release is unusually easy to summarize:
- For NTP, choose the largest ByteShape model that fits your hardware and context needs.
- For MTP on GPUs, do the same, but remember that the extra memory footprint can change what fits. On 24+GB GPUs,
MTP-GPU-5is the default recommendation. On 16GB GPUs,MTP-GPU-2is the practical choice. - For CPUs, stick with NTP for now.
We are not covering KLD or perplexity in this release post. In our experience with instruction-tuned models, they are useful for catching clearly broken quantizations, but once models are roughly in the right range, we have not found them to reliably predict downstream benchmark performance. We will discuss this, along with how we approach evaluation, in a dedicated blog post.
As always, the best model is not the smallest model, the fastest model, or the model that wins one diagnostic metric. The best model is the one that fits your hardware and gives you the best quality-speed trade-off for the workload you actually run. That is what this release is designed for.